
Why does a voice sound disordered? Does it sound harsh? Does it sound breathy? Does it sound too high pitched? We can hear a voice and perceptually tell that it sounds unnatural. How do we prove this? There are perceptual scales, like the CAPE-V and the GRBAS, and I use the Vanderbilt FITQ scale. (It’s a rating scale for Frequency, Intensity, Timing and Quality on a 0-3 rating.) There are self-perception measures like the Vocal Handicap Index and the Reflux Symptom Index. Unfortunately, we can’t just say someone sounds dysphonic and expect the service to be covered. Insurance companies tend to prefer hard numbers and measurable data. The perceptual scales are measurable, however they are subject to intra and inter rater reliability issues because on any given day each of us hears things differently.
Many clinicians utilize acoustic measures like Jitter and Shimmer, as well as noise-to-harmonic ratio when they gather data. Jitter is displacement in frequency periods or pitch variations, and shimmer is changes in intensity or amplitude. Noise-to-harmonic ratio is simply comparing the relationship of good sounds to bad ones, and if the noise outweighs the harmonies, then there is dysphonia. These measures are limited because they require the person to sustain a vowel to capture data, and that can be difficult for some voice patients. While it is important to measure sustained vowel productions, but it is vital to measure the voice in connected speech as well. There are reasons for this: 1) Adductor spasmodic dysphonia sounds relatively normal during a sustained “ahh” but is very apparent during connected speech. 2) Sustained vowels are not as multidimensional as speech. Speech contains rapid voice onsets, offsets, inflections, stress, pauses, voiced and non voiced sounds.
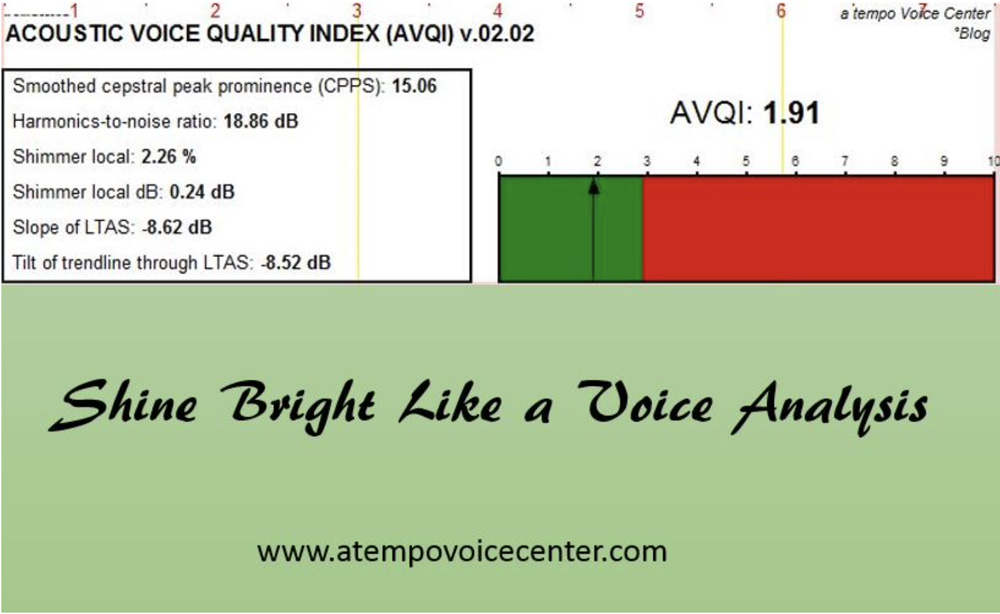
What if we could somehow combine how we measure both connected speech and prolonged vowels? Youri Maryn, Marc De Bodt and Nelson Roy developed a protocol that is multifaceted, like a diamond. The voice has many layers and dimensions, so shouldn’t it be analyzed the same way? It’s called the Acoustic Voice Quality Index. It takes into consideration 6 parameters: shimmer local, shimmer local dB, harmonics-to-noise ratio, general slope of spectrum, tilt of regression line through the spectrum and smoothed cepstral peak prominence. If these are unfamiliar terms, that’s okay. Just know that the sound signal is being analyzed in different ways and tested to determine if the numbers accurately reflect what is heard perceptually. The testers in this article are making sure that if a voice quality sounds disordered, the numbers consistently reflect this when compared with numbers from a normal sounding voice.
Cepstral peak prominence is an emerging measure for acoustic analysis. (Cepstrum is spectrum with the letters rearranged, but it the calculations to find it are a bit more involved.) The more periodic a sound signal is, the more you will see a prominent cepstral peak, so we are looking for a low number to represent a dysphonic voice. The great thing about cepstral peak is that it is the only acoustic metric that shows dysphonia in sustained vowel productions and connected speech. Jitter, Shimmer and NHR are limited to the former.
Simply by using PRAAT, a free program, you can easily obtain data in a non-invasive way. Maryn et al 2010 says that there are other similar models of voice data analysis, but none utilize continuous speech and sustained vowels to determine how severe a person’s dysphonia is. Maryn and team cross-validated the AVQI in 2009 with 251 subjects. This 2010 study looked at 72 voice samples, as well as 33 other samples to determine the AVQI’s responsiveness to change. Acoustic measures were taken using James Hillenbrand’s “SpeechTool” (another free program) and PRAAT.

AVQI was developed specifically to be widely available to those providing voice therapy with limited budgets. It’s super nice to have CSL software from Kay Pentax, but for the vast majority of clinicians in hospitals, private practices, schools and clinics, budgets are tight. PRAAT can be downloaded on Mac or PC, so it is easily accessible. If you were like me, you might have been collecting data with PRAAT and SpeechTool, but with this measure you can streamline your data collection and use only one program. This saves you time and money, as well as provides you with better data. Excellent… The script necessary to complete calculations can be found in the appendix data for Maryn 2014.
So why the AVQI? Maryn and Weenink found that listeners rate sustained vowels more severely than connected speech when there is dysphonia present. I can vouch for this because my patients usually can only hear a target production in isolated sustained vowels, not in connected speech when I demonstrate both. The AVQI has also been tested across multiple languages, like Dutch and German. Studies have found that despite language differences, the measure remains reliable and valid.
The 2014 article cautions for clinicians to make sure they are accounting for environmental noise in the room as well as mobile phone interference. Recommendations are for a head-mounted condenser microphone with XLR connection as well as an external mixer soundcard to improve the quality of the audio signal and to keep it the same across patients. Remember to tilt the microphone away from the mouth and record voice sounds with a sampling frequency of at least 26kHz.
Using the AVQI has allowed me to streamline my evaluations by a few minutes, as well as show a picture representation of the voice to my patients. Visual is always good. Minutes of each day all are precious because they add up, so I hope you will read up on this available and easy-to-use option for acoustic measurements.
-ATVC
Resources: The Acoustic Voice Quality Index: Toward improved treatment outcomes assessment in voice disorders Youri Maryn, Marc De Bodt, Nelson Roy. Journal of Communication Disorders 43 (2010) 161–174
Objective Dysphonia Measures in the Program Praat: Smoothed Cepstral Peak Prominence and Acoustic Voice Quality Index. Marin, Youri & Weenink, David. J Voice. 2015 Jan;29(1):35-43. doi: 10.1016/j.jvoice.2014.06.015. Epub 2014 Dec 9.
Kristie Knickerbocker, MS, CCC-SLP, is a speech-language pathologist and singing voice specialist in Fort Worth, Texas. She rehabilitates voice and swallowing at her private practice, a tempo Voice Center, and lectures on vocal health to area choirs and students. She also owns and runs a mobile videostroboscopy and FEES company, Voice Diagnostix. She is an affiliate of ASHA Special Interest Group 3, Voice and Voice Disorders, and a member of the National Association of Teachers of Singing and the Pan-American Vocology Association. Knickerbocker blogs on her website at www.atempovoicecenter.com. She has developed a line of kid and adult-friendly therapy materials specifically for voice on TPT or her website. Follow her on Pinterest, on Twitter and Instagram or like her on Facebook.

